
I'm a software engineer. Part of my current job is building out an Autonomous Agentic AI SDLC for my whole org, and the biggest piece of it is a full pipeline that covers product intake, PRD, architecture, specs, implementation, and code review. It's a multi-repo enterprise setup: sandboxing, autonomous fix loops, GitHub Actions wiring everything together, and a whole cast of specialized agents handing work down the line. An end-to-end agentic SDLC is roughly where the whole industry is heading right now. Everyone is racing to build some version of it, each with their own flavor. This is the one I built.
It's great. It's also big. It assumes multiple repos, a tracker like Linear, CI runners, and a team of humans sitting at the gates. That's the right shape when you've got a real engineering org behind it. But it left me with a question I couldn't shake:
Would the same pipeline work for one developer?
So I went and found out. And I made the test as unfair to myself as I could.
It's easy to fool yourself here. Pick a stack you know cold, build something you've built a dozen times, and of course it "works." You'd have caught every mistake on reflex anyway. That tells you nothing about the pipeline. It just tells you that you're good at your job.
So I stacked the deck against myself two ways.
First, a stack I'd never touched. I went with Flutter and Flame. I had never written a line of Dart in my life. If the pipeline could carry me through a stack I didn't understand, where I couldn't quietly cover for a weak agent with my own experience, then a passing grade would actually mean something.
Second, pure code with no scene editor. Flutter and Flame is code all the way down. No Unity scenes, no binary files that don't diff in git, no visual editor doing work the agents can't see. Everything an agent needs to reason about lives in plain text it can read and write. That's the kind of environment agents are happiest in, and it kept the experiment about the pipeline instead of about gluing tools together.
The thing I'd build to put it all through its paces is Colors Grid, a fast little arcade game.
It's a reflex game. You get a 3x5 grid of colored rings. A horizontal line and a vertical line sweep across the grid at their own speeds, bouncing off the edges and changing color as they go. When a line crosses a ring, you tap it (or swipe it). If the ring's color matches the line's current color, you score. Get the color wrong and you lose points.
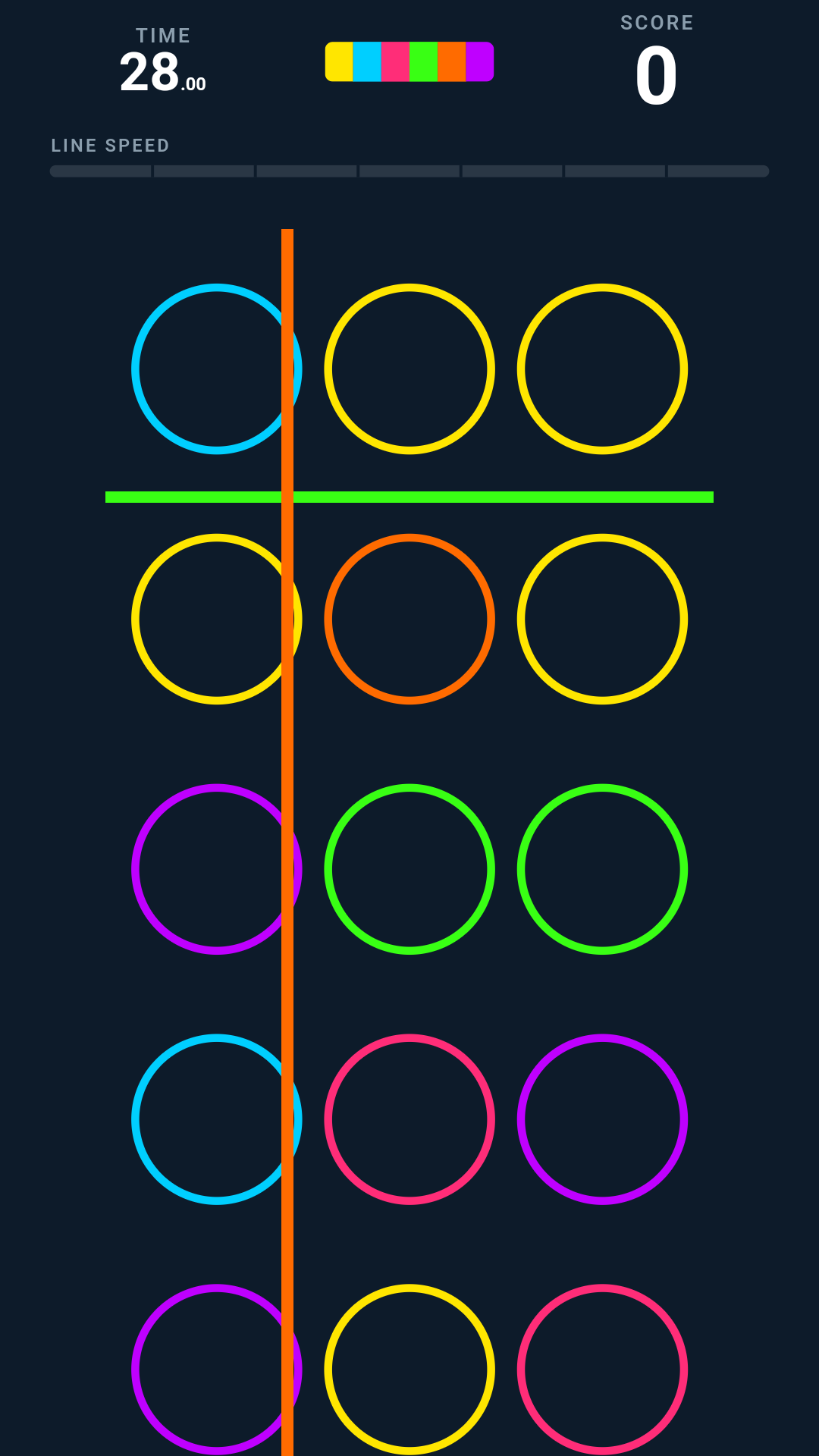
There's a lot more sitting on top of that loop than you'd expect. A countdown timer that correct hits extend. A roll-bar multiplier that charges as you chain hits. Swipe combos. A 3x bonus when a cell sits right where both lines cross. Spendable power-ups like Time Burst, Color Spread, and Rainbow Cell. Every correct hit fires a sound and a haptic buzz, so the whole thing feels physical in your hand.
That's one mode. There's a second one I added later, Puzzle (Color Shift), for when you'd rather plan than panic. Same grid, same colors, but nothing moves on its own. You slide a horizontal and a vertical line one step at a time; when a line lands, the matching cells in that row or column advance to their next color, and the line's own color cycles on. The goal is to walk every cell through all six colors in as few moves as possible. No timer, no fail state, just a clean little logic puzzle that reuses the exact same shapes and color packs as the arcade mode, with its own free-unlock track gated on boards solved instead of high score.

And then there's the meta layer: 27 shapes, a pile of color packs, 24 sound packs, 24 background-music packs. You unlock them either by hitting score thresholds or by buying them, and there's a premium subscription that strips out ads and unlocks everything. Underneath all that sits an ad service and a full in-app purchase and subscription system.
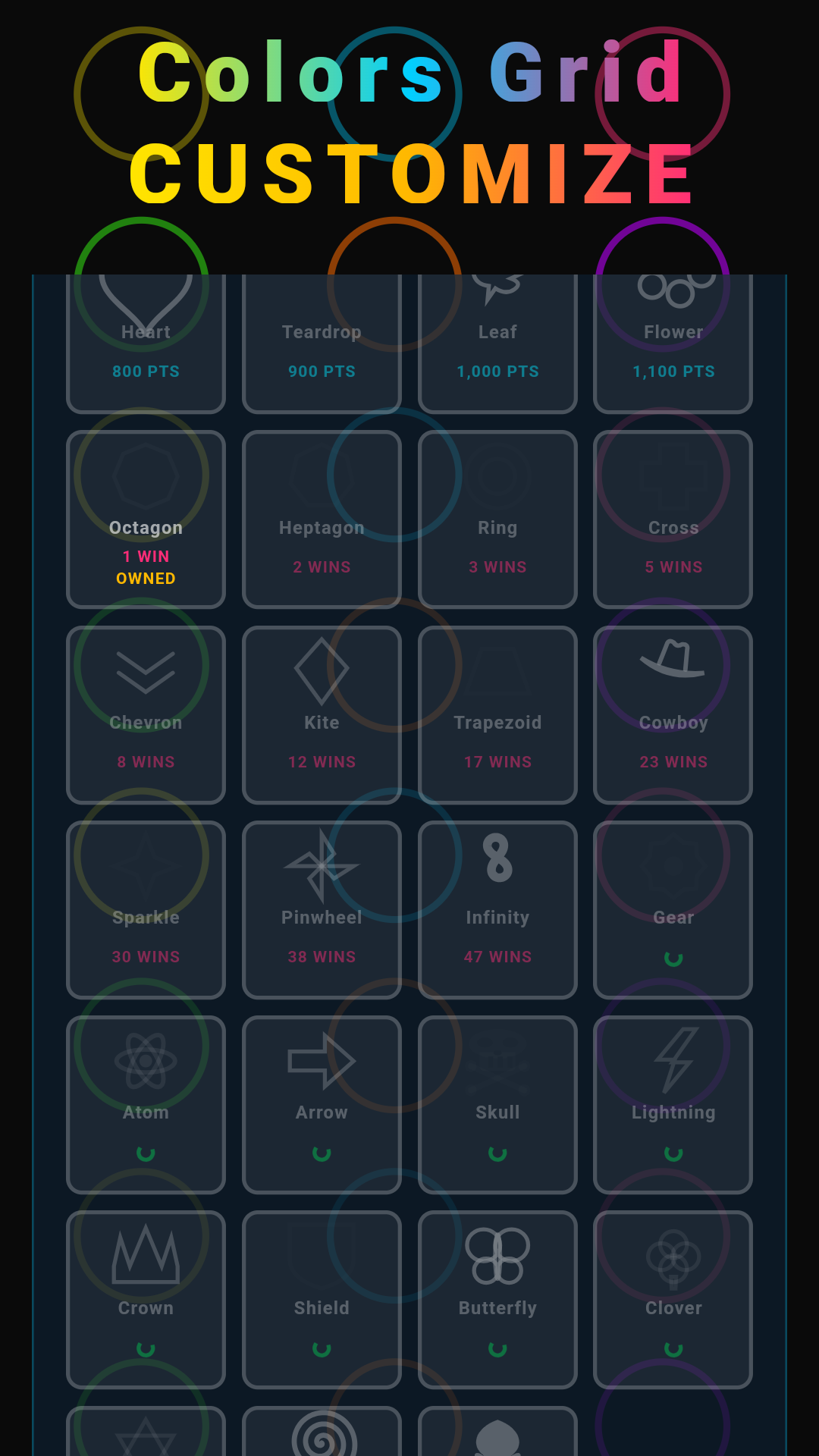
That breadth was the whole point. It gave the pipeline real, varied work to chew on (two game modes, UI screens, a Flame game loop, services, IAP, ads, persistence) instead of some toy CRUD app.
If you want to see what all of that adds up to, Colors Grid has a home page here.
Before I shrank anything, here's the shape of the full thing. None of this is unique to me. It's roughly the assembly line the whole industry is converging on for agentic SDLC. Everyone's building their own flavor; this is the order mine runs in, one sentence per step.

Product definition
Architecture & design
UI contract (frontend work only)
Specs
Implementation
Code review (self-healing)
Delivery
That's twenty steps, five human gates, and everything in between running on its own.
The enterprise version sprawls across many repos, with CI and a tracker holding it all together. For Colors Grid I collapsed every bit of that down to one repo and two slash commands.
/new-feature runs a Product Owner interview, writes a PRD, and opens a draft PR.
/run-pipeline takes the approved PRD and drives the rest of it: spec generation, spec review, implementation, feature-spec review, coding-standard review, summary update, regression, and a final report. The review steps are self-healing. When a review finds a problem, it spins up a fix and re-reviews on its own, instead of dropping the failure back in my lap.
No Linear. No GitHub Actions. No separate Modal or CI jobs. The autonomous steps that used to be distributed services now just run as fresh subagents in throwaway git worktrees, right on my laptop.
The interesting part is how little the core shape had to change. It's still PRD intake, a human gate, autonomous spec generation, review, self-healing fix loops, implementation, more review, a summary, and a report. Same skeleton, a tiny fraction of the infrastructure. That by itself was worth the experiment. The value was in the structure and the gates, not in the heavyweight plumbing I'd assumed was holding everything up.
Here's what those twenty steps collapsed into. Most of the consolidation comes from the constraints falling away: one repo instead of many, one platform instead of four, and one person standing at every gate. The first command, /new-feature, folds intake, the product-owner interview, and a scope-and-dependency check into a single conversation that ends in a PRD and a draft PR. The second, /run-pipeline, drives the rest:
summary.md and a feature-sizing rubric, then auto-advances if it passes. Why it works solo: the rubric is what stops me from quietly green-lighting my own oversized ideas.main, where every cold subagent downstream can read it. Why: main is the one place a fresh agent always knows to look.summary.md, the single source of truth for "what already exists." Why: it's the shared memory every future agent inherits./tmp. Why: worktrees are the laptop-sized stand-in for the enterprise version's cloud sandboxes, isolation without the infrastructure.summary.md with the new screens, components, providers, and services. Why: same shared memory, kept current for next time.No Linear, no GitHub Actions, no cloud runners. Two slash commands on one laptop, and I can fire and forget.

There's one real cost to doing it this way. Because everything shares a single local clone and each feature lives on its own branch, I can't run two full pipelines at once: they'd fight over which branch is checked out. The enterprise version sidesteps this entirely with real per-repo, per-feature cloud sandboxes; my laptop version trades that away for simplicity. The one exception is the small, direct-prompt tweaks I keep on the main branch: as long as I tell each session to stay on main, nothing collides over branches, and I can fan several of them out in parallel. So I get concurrency back exactly where I do the most iterating.
For anything with real, definable scope (a new service, a non-trivial flow, anything cross-cutting) the full pipeline paid off every single time. Take the ad service or the IAP and subscription system. The PRD to spec to implementation to review chain forced enough thinking up front that the agents usually one-shot the whole feature without me jumping in halfway.
And the headline result is exactly what I'd hoped for: I can fire and forget. I kick off /run-pipeline, walk away, and come back to a merge-ready PR with a summary waiting for me. The cost is tokens. The full loop of generating, reviewing, and fixing burns a lot of them. But for anything where correctness matters, that's a trade I'll take every time. Tokens are cheap compared to my attention.
I want to be careful here, because it would be easy to misread this as "the SDLC is for code and not for game feel." That's not it. The pipeline works whenever you know exactly what you want ahead of time, and it keeps working even after the bulk of a thing is built and you're back making adjustments. The real question is never code-versus-feel. It's whether the change is big enough to be worth it.
That's where the game itself tripped me up. The moment-to-moment feel of tapping, the line speeds, how big a score pop should be, how a power-up reads on screen: tuning those isn't one definable change, it's a stream of tiny ones. Dozens of micro-adjustments an hour: play it, notice something, nudge it, play it again. Each individual tweak is so small that wrapping a PRD, specs, and a review chain around it costs far more than the change is worth. The ceremony dwarfs the work.
So for that kind of iterating I just drop into Claude Code directly and prompt it. Instant feedback, no ceremony. It's not that the SDLC can't touch game feel. It's that the pipeline pays off in proportion to the size of the change, and these were about as small as changes get.
So I didn't end up with one process. I ended up with two, and a sense for which one I'm in. Full SDLC when I know what I want and the change is substantial: a whole new mode like Puzzle, the ad service, IAP, subscriptions, a new screen. Direct prompting when the changes are small and exploratory, where I want a tight back-and-forth loop and each step is barely bigger than the last.
Here's the part that genuinely surprised me. I started this not knowing a line of Dart, and I never actually sat down to study it. But monitoring the pipeline turns out to be a slow-drip tutorial. I read every PRD, every spec, and every diff as they went by. I watched the self-healing reviews catch mistakes and explain why they were mistakes. I saw the same Flutter, Flame, and Riverpod patterns show up over and over until they stopped looking foreign.
By the end I could read the code, spot when something was off, and write the precise prompts to fix it myself, which is exactly what made the direct-prompting loop for game feel possible in the first place. I picked up the stack as a side effect of supervising the machine that was using it. And, not for nothing: the game is genuinely fun, so all that monitoring never felt like a chore. The thing I set up as an unfair test of the pipeline quietly taught me a new stack along the way.
If I had to pick one lesson to underline, it's this: how you scaffold the project at the start decides how well the agents do later.
A fresh subagent shows up cold with zero memory of anything that came before. The only reason it can pick up a task and get it right is the scaffolding around it. Clear conventions. A sane directory layout. A single source of truth for what already exists (I keep a living summary.md for exactly this). And solid house-style docs in AGENTS.md that pin down the Dart, Flutter, Flame, and Riverpod conventions. Get all that right early and every agent after that inherits it for free. Get it wrong, or write it too late, and every agent re-argues the same decisions and slowly drifts.
The pipeline is only ever as good as the project it runs on. The work isn't really in the agents. It's in the soil you plant them in.
I know this one sounds like heresy, so let me be careful about it. I pulled the automated testing steps out of this pipeline. Two reasons, both specific to this project.
The game is the regression test. The fastest way to catch a regression in Colors Grid is to play it for thirty seconds, and since it's actually fun, that's no chore. For a client-side game with no backend, playing it catches what matters.
And tokens, again. Writing, reviewing, and running full test suites inside the pipeline is one of the most expensive things it does. For a small game with no server behind it, that overhead just wasn't worth it.
flutter analyze still runs before every commit, so I keep the static safety net. This isn't a blanket recommendation. For the enterprise pipeline, the tests stay. This was a scale-appropriate cut for a solo game project, which is the whole spirit of the experiment anyway.
Yeah. The experiment answered its own question. A heavyweight, multi-repo, enterprise AI SDLC really can be scaled down to one developer and one repo without losing the thing that made it worth having. It carried me through a stack I'd never used, shipped real features while I was off doing something else, and cost me tokens instead of hours.
But the lesson underneath it is about fit. The pipeline isn't a hammer for every nail. It's the right tool for scoped, correctness-sensitive work, and the wrong tool for tight creative iteration. The real skill as a solo developer is knowing which mode you're in at any given moment. Full SDLC for the plumbing. Direct prompting for the feel. And a well-scaffolded repo under both of them, so every agent you call up lands on solid ground.
And honestly, that's the part I keep coming back to. I'd always wanted to build a game and never had the chance. The time, the team, the right moment never quite lined up. But with how fast AI is moving, and with the whole industry racing to stand up autonomous, agentic SDLCs, this was finally the excuse to do both at once: build the game I'd always meant to, and find out what one of these pipelines can really do in the hands of a single developer. Colors Grid is the game I wanted. The pipeline is how I finally got to make it.
You can check out Colors Grid here: techtiger.tech/colors-grid-home.
